

 中文
中文 
yang654321 deepin
deepin
2021-05-12 18:06 deepin 升级了,pip3 install --upgrade pip命令运行已经提示需求已满足
requirement already staisfied:pip in /usr/local/lib/python3.7/dist-packages(21.1.1)
Reply Like 0 View the author
 deepin
deepin 升级了,pip3 install --upgrade pip命令运行已经提示需求已满足
requirement already staisfied:pip in /usr/local/lib/python3.7/dist-packages(21.1.1)
deepin 依旧是failed to build pikepdf,和原来出错提示一样

 deepin
deepin 依旧是failed to build pikepdf,和原来出错提示一样
先尝试
sudo apt install qpdf安装下qpdf,没问题的话再安装pikepdf
deepin qpdf安装了,但是sudo apt install pikepdf 无法安装,提示无法定位软件包pikepdf,软件源没有pikepdf的原因?
deepin qpdf安装了,但是sudo apt install pikepdf 无法安装,提示无法定位软件包pikepdf,软件源没有pikepdf的原因?
uos仓库里面没有pikepdf ,pikepdf 是python的模块
pip3 install pikepdf pip3 install pikepdf还是提示错误failed to build pikepdf
deepin pip3 install pikepdf还是提示错误failed to build pikepdf
你看下这里吧。
https://github.com/jbarlow83/OCRmyPDF/issues/460
不行我也没办法了。
deepin github上的东西还不会弄,水平不够,而且,而且网站也打不开 ,算了,放弃研究先,多谢回复帮助!
,算了,放弃研究先,多谢回复帮助!
 deepin
deepin 这是什么下载链接!百度?终端上用的?
deepin 这是什么下载链接!百度?终端上用的?
蓝奏云,这几天炸了,这是新连接
https://wwa.lanzoui.com/iHX2Hp1nr8j

 deepin
deepin utools里面就有ocr
deepin utools里面就有ocr
不一样的。

他的只是单纯的对图片进行ocr识别,我的是识别pdf文件并且生成文字层。
Popular Ranking
ChangePopular Events
More
(更新时间2021.05.13,更新下载链接)
修复说明
1.增加了python3-pip这个依赖,之前安装失败因为没有这个,因为要安装python模块ocrmypdf。系统默认是没有安装pip3的。
2.在安装完成后安装ocrmypdf之前增加了升级pip3的命令,避免因pip3版本太低无法安装pikepdf模块
3.安装了我之前发出来的版本的话,在安装这个版本之前请使用
进行删除。千万不要点重新安装!!!
4.修复了deb包重新安装有问题的bug。(2021.05.12新增)
简介
PDF OCR识别工具是一款对单个的PDF扫描件进行OCR识别的一款小工具。
deb包仅支持amd64架构!!!
功能
对PDF文件进行OCR 识别并在原PDF上添加一个识别结果文本层。
软件截图
温馨提示
由于使用的OCR识别模块原因(其实还是因为我太菜了),进度条的功能比较难实现。
所以点击识别按钮后,整个界面不会给出任何提醒,界面卡着就是在正常识别。识别完成了会有提示弹出来的。
不建议添加太大的文件,除非你散热良好。因为识别时没有做任何限制,你cpu占用率是会直接到100%的,长时间识别会使电脑发热严重。
识别过程中不建议继续进行其他操作,因为会有点卡。
使用说明
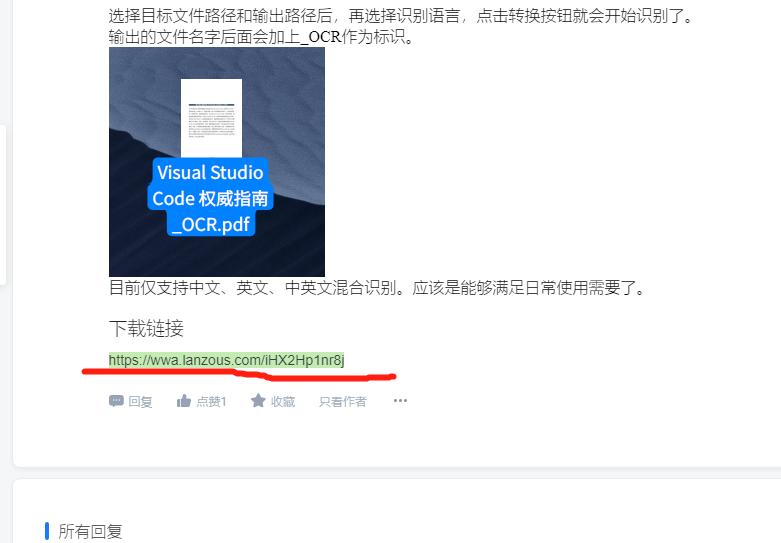
选择目标文件路径和输出路径后,再选择识别语言,点击转换按钮就会开始识别了。
输出的文件名字后面会加上_OCR作为标识。
目前仅支持中文、英文、中英文混合识别。应该是能够满足日常使用需要了。
下载链接
https://wwa.lanzoui.com/iHX2Hp1nr8j