

 中文
中文 
lcw0268 deepin
deepin
2021-05-11 20:12 deepin It has been deleted!
 deepin
deepin 
 deepin
deepin 支持,顺便问问有没有arm64版的。

 deepin
deepin 支持,顺便问问有没有arm64版的。
没有设备啊做不了包。
https://wwa.lanzous.com/iNsw6p0pqof
用这个吧,双击run.sh,选择在终端中运行即可。
第一次使用先双击install_depends.sh,选择在终端中运行,安装一次依赖。
安装依赖没问题的话应该是能用的。
deepin 好的,谢谢,我试试。晚点反馈使用情况。
deepin 不行,在终端里运行安装完依赖后自动关闭终端了,再双击run.sh在终端里运行貌似有个什么界面一闪就没了,然后没有其他后续反应,后台也没见有程序运行。
deepin 安装依赖之前好像pip没安装成功,我去百度用了两个命令安装才能继续下去的。
sudo apt install python3-pip
sudo pip3 install --upgrade pip
deepin 终端里用pip3 -v能查看到pip3的使用说明,没有提示错误,应该是成功安装了pip3
deepin 安装依赖之前好像pip没安装成功,我去百度用了两个命令安装才能继续下去的。
sudo apt install python3-pip
sudo pip3 install --upgrade pip
你的是deepin吗?
deepin uos
deepin uos
我uos 64位版本没有任何问题,可能是安装命令有所差异,将依赖安装脚本的python3-pip安装命令和pip3升级命令修改下就好了
deepin uos
程序能够成功运行吗?OCR识别有没有问题?
顺便好奇的问一下你的是什么设备
deepin 没出ui界面,应该是没成功运行。我的是uos专业版1022,宝德pt620K,huawei kunpeng 920 2251k cpu,16G内存,arm64构架的
deepin pip3是否安装成功,不是用pip3 -v看提示信息判断吗?不成功应该有错误提示吧,我这里没有错误提示,而是提示pip3的各种使用说明参数。
deepin pip3是否安装成功,不是用pip3 -v看提示信息判断吗?不成功应该有错误提示吧,我这里没有错误提示,而是提示pip3的各种使用说明参数。
不一定是pip的错误。你在终端里面运行
python3 /opt/apps/nexfia.pdf-ocr/PDFOCR.cpython-37.pyc 看下报什么错误
deepin 提示无法打开对应的.pyc文件,没有对应的文件在该路径。
我去对应目录/opt/apps/查看了,没有nexfia.pdf-ocr目录。
deepin 直接在原解压包的路径运行该文件如下截图
deepin 直接在原解压包的路径运行该文件如下截图
我忘记修改run.sh了,需要把里面内容替换为
#!/bin/bash
python3 ./PDFOCR.cpython-37.pyc直接在原解压包的路径运行该文件如下截图
pip3 install ocrmypdf
deepin 安装有问题,安装过程提示如图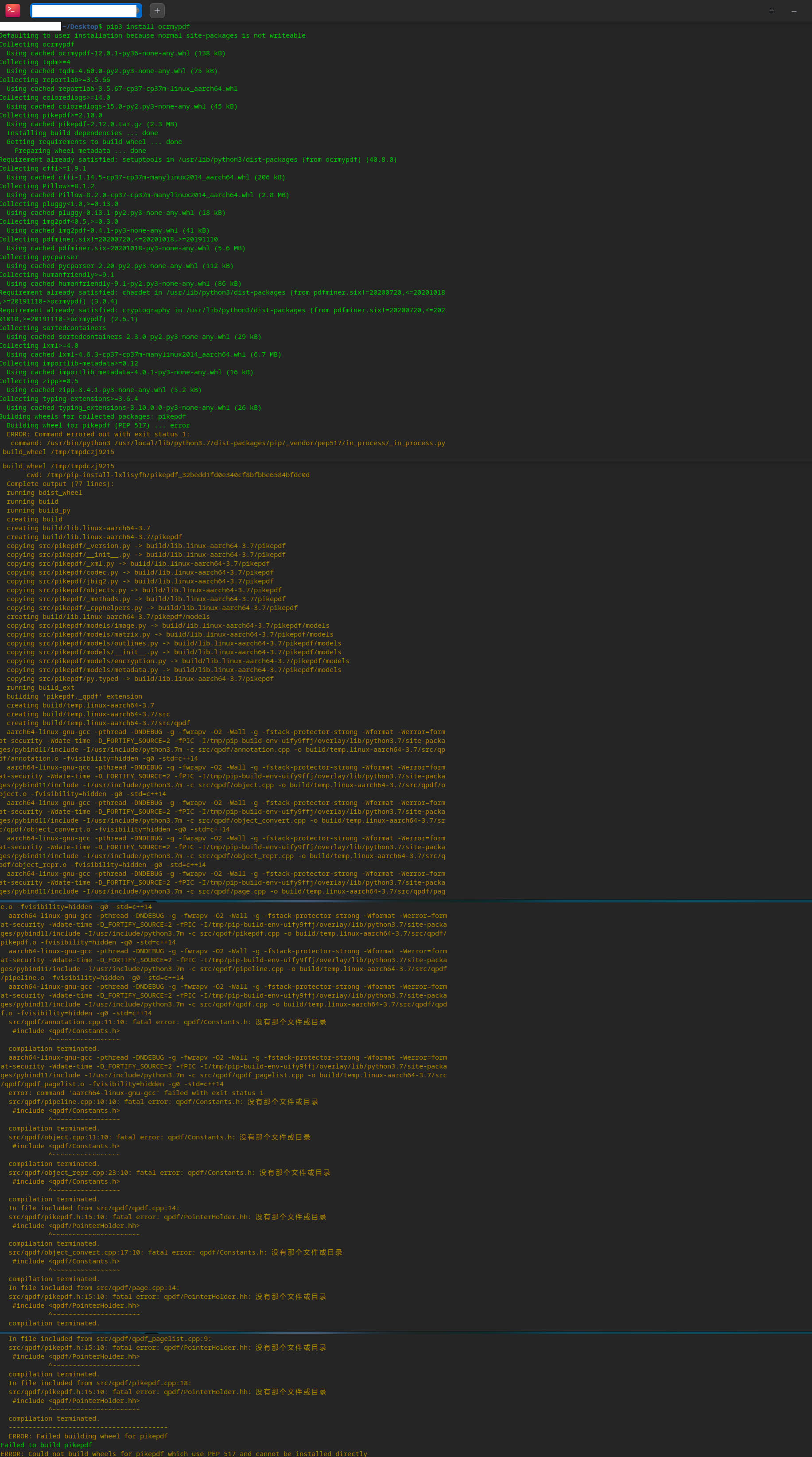
deepin 安装有问题,安装过程提示如图
升级pip3了没?升级了再安装试试
Popular Ranking
ChangePopular Events
More
(更新时间2021.05.13,更新下载链接)
修复说明
1.增加了python3-pip这个依赖,之前安装失败因为没有这个,因为要安装python模块ocrmypdf。系统默认是没有安装pip3的。
2.在安装完成后安装ocrmypdf之前增加了升级pip3的命令,避免因pip3版本太低无法安装pikepdf模块
3.安装了我之前发出来的版本的话,在安装这个版本之前请使用
进行删除。千万不要点重新安装!!!
4.修复了deb包重新安装有问题的bug。(2021.05.12新增)
简介
PDF OCR识别工具是一款对单个的PDF扫描件进行OCR识别的一款小工具。
deb包仅支持amd64架构!!!
功能
对PDF文件进行OCR 识别并在原PDF上添加一个识别结果文本层。
软件截图
温馨提示
由于使用的OCR识别模块原因(其实还是因为我太菜了),进度条的功能比较难实现。
所以点击识别按钮后,整个界面不会给出任何提醒,界面卡着就是在正常识别。识别完成了会有提示弹出来的。
不建议添加太大的文件,除非你散热良好。因为识别时没有做任何限制,你cpu占用率是会直接到100%的,长时间识别会使电脑发热严重。
识别过程中不建议继续进行其他操作,因为会有点卡。
使用说明
选择目标文件路径和输出路径后,再选择识别语言,点击转换按钮就会开始识别了。
输出的文件名字后面会加上_OCR作为标识。
目前仅支持中文、英文、中英文混合识别。应该是能够满足日常使用需要了。
下载链接
https://wwa.lanzoui.com/iHX2Hp1nr8j