

 中文
中文 
Feelup deepin
deepin
2025-02-12 09:14 deepin 观摩:
我还真尝试了这个,
结果不太懂,下载了一个gguf的文件,加载之后,竟然不支持中文。

不支持中文的大模型倒是很少哦。一般就是它使用英文回答你问题,但你要是告诉它使用中文进行回答,它也会用中文的。
Reply Like 0 View the author
 deepin
deepin 我还真尝试了这个,
结果不太懂,下载了一个gguf的文件,加载之后,竟然不支持中文。
不支持中文的大模型倒是很少哦。一般就是它使用英文回答你问题,但你要是告诉它使用中文进行回答,它也会用中文的。
 deepin
deepin 不支持中文的大模型倒是很少哦。一般就是它使用英文回答你问题,但你要是告诉它使用中文进行回答,它也会用中文的。
嗯,我用中文提问的,也用中文或者翻译的英文让他切换中文。
结果,它一直给我回答什么数学题,搞不明白咋回事,删了
deepin 嗯,我用中文提问的,也用中文或者翻译的英文让他切换中文。
结果,它一直给我回答什么数学题,搞不明白咋回事,删了
这个应该是模型的接收提问的格式与ollama不匹配导致的。你只能去找一个适合的模型了。
比如这个:https://hf-mirror.com/bartowski/gemma-2-2b-it-GGUF/tree/main
我用了这个版本:gemma-2-2b-it-Q8_0.gguf
回答还是很正常的

 deepin
deepin 这个APIkey填什么?不填好像提示连接失败


我也遇到这个问题了
deepin 我也遇到这个问题了
多检查一下,应该都是能解决的,你需要的信息都能在这个贴子里面找到。
 deepin
deepin 3213131
 deepin
deepin 请问有朋友试过双 3060TI16G显存接入DeepSeek吗?有没什么注意事项?
 deepin
deepin sudo vim /etc/systemd/system/ollama.service
怎么修改ollama服务配置?在终端删除原有内容,粘贴修改的内容,怎么保存?
deepin sudo vim /etc/systemd/system/ollama.service
怎么修改ollama服务配置?在终端删除原有内容,粘贴修改的内容,怎么保存?
在vim编辑器中
-- 按 “i” 键进入编辑模式,此时可以对文件进行编辑操作
-- 按 “Esc” 键进入命令模式,此时可以执行vim编辑器命令; 此时光标会移到左下角,输入冒号 “:”,在冒号后面继续输入 “wq”,按回车键即可保存。
deepin 运行安装命令,提示无法创建目录 /usr/share/ollama。。。。。难道是需要sudo吗?
deepin 运行安装命令,提示无法创建目录 /usr/share/ollama。。。。。难道是需要sudo吗?
对,是需要sudo权限的
deepin 对,是需要sudo权限的
谢谢。
 deepin
deepin sudo systemctl enable ollama.service
无法运行的话,执行以下上面的命令
 deepin
deepin 别的模型也能用吗?
deepin 别的模型也能用吗?
ollama.com 网站上的模型都可以用。
deepin 
 deepin
deepin sudo systemctl start ollama
Failed to start ollama.service: Unit ollama.service not found.
???
deepin sudo systemctl start ollama
Failed to start ollama.service: Unit ollama.service not found.
???
你参考一下这个部分的内容
 deepin
deepin 不如用腾讯出品的ima😁
deepin 牛
Popular Events
More

最近想要在Deepin系统上部署本地 DeepSeek-R1 模型的话题越来越多了,虽然不是太复杂,但看了好几个帖子都感觉写得不够详细,对新手也不够友好,我就来写一个稍微详细点的吧
说明:本流程不仅仅适用于 DeepSeek-R1 模型,同样也适用于其它模型的本地部署
演示使用的系统版本与硬件条件
Ollama部署
打开网站:Ollama软件 ,点击复制命令
将该命令粘贴到终端中执行即可,安装过程中需要输入当前用户的密码
命令:
curl -fsSL https://ollama.com/install.sh | sh说明:ollama软件大概有1.5GB左右,下载需要一些时间(下图所示还没开始下载哦,下载开始后会显示下载速度等信息)
ollama下载完成后,就可以正常查看软件版本
命令:
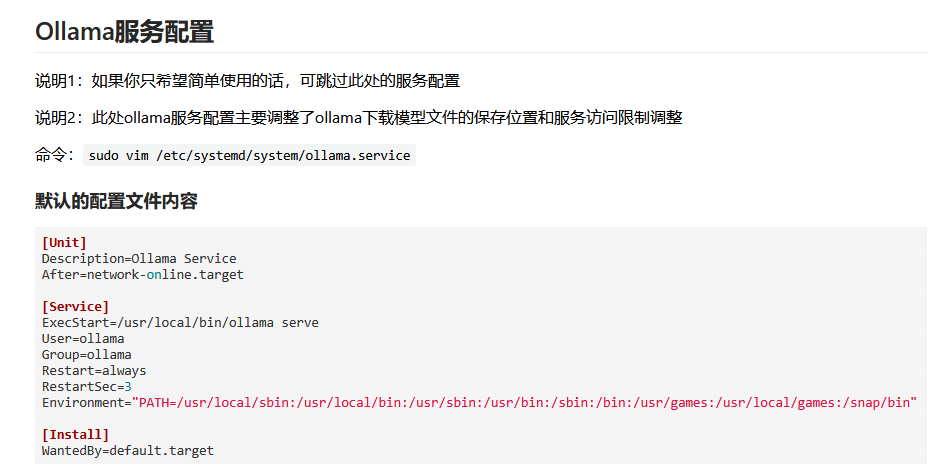
ollama --versionOllama服务配置
说明1:如果你只希望简单使用的话,可跳过此处的服务配置
说明2:此处ollama服务配置主要调整了ollama下载模型文件的保存位置和服务访问限制调整
命令:
sudo vim /etc/systemd/system/ollama.service默认的配置文件内容
非Deepin 25系统服务修改参考
该ollama服务配置适用于Ubuntu、OpenEuler、RedHat、Deepin 23等大多数系统
Deepin 25系统服务修改参考
由于Deepin 25采用了不可变系统的设计,ollama安装完成后,程序的执行文件位置出现了一些变化
在进行ollama服务配置时也需要做相应的修改(否则服务会运行异常)
Ollama服务启动
更新服务配置:
sudo systemctl daemon-reload重启ollama服务:
sudo systemctl restart ollama.service查看ollama服务运行状态:
systemctl status ollama.service模型下载
打开网站:Ollama网站模型搜索
搜索框中搜索需要下载的模型名称关键字,由于 DeepSeek-R1 模型是最近发布的热门基座大模型,此时的排序在最前面,直接点击进入即可
根据自己的电脑配置,选择合适大小的参数模型,点击复制模型下载命令
将复制的命令粘贴到终端中进行下载(本例中选择下载 1.5b 参数量大小的模型)
模型下载完成后会自动运行,此时就可以在终端中与它进行对话了
命令:
ollama run deepseek-r1:1.5b说明:不是因为我的电脑配置太差哦,而是这个大小的模型响应速度最快,日常使用时我的电脑风扇都不会转一下的(思考太过复杂的问题时,还是会转的,风扇没有坏),内存占用也很低(大概占用1.3GB的内存),非常好用。毕竟是推理模型,比起普通的聊天模型,它会尝试思考验证自己的想法是否正确,也就是说,模型本身的知识量只是它思考的参照物,它能做的事是远超已投喂知识数量的哦(在能够得到正确引导的前提下)。
如果以后想在终端中运行该模型的话,也是继续使用上面的命令哦。
下面是一个简单的运行示例
在UOS AI中添加本地模型
当然了,虽然终端中可以正常使用DeepSeek模型,但毕竟不太方便,还是使用图形化的访问方式体验才会更好。下面我们在UOS AI中添加DeepSeek R1。
打开UOS AI的设置选项
在模型配置中选择“私有化部署”,点击“添加”
在添加窗口中参考如下内容进行填写,填写完成点击确定即可
本例中使用到的信息
点击确定后,程序会验证对应的大模型是否可用(显示转圈)
验证完毕后,会显示已经成功添加的本地模型
添加完成后,就可以在UOS AI中选择 DeepSeek R1 模型进行使用了
.
.
.
附录
01:Ollama模型下载页面的部分信息说明
在Ollama模型的下载页面,你可能也注意到了下面的这些信息,
第一部分
“1.5b, 7b, 8b, 14b, 32b, 70b, 671b” 表示本页提供的模型参数的数量规模
“9M Pulls” 表示该模型已经被下载了9百万次
"Updated 2 weeks ago" 表示该页面或模型资源上一次更新是在两周前
补充:“28 Tags” 表示与该模型相关的标签数量是28个,不同的标签用于标识模型的不同版本、配置等
第二部分
"Updated 2 weeks ago" 表示该模型资源上次更新是在两周前
“0a8c26691023 · 4.7GB” 表示该模型文件的标识符与大小
model行:模型信息
params行:参数信息
template行:模板信息
license行:采用的许可证
02:ollama服务的进一步配置
默认情况下,ollama启动一个大模型后,你要是5分钟不使用的话,ollama就会关闭该模型 (释放内存),当你再次使用该模型时,ollama会再次启动该模型 (将模型载入内存),当模型文件比较大时,体验就会不太好。
而且,在多人使用时,大家同时对大模型进行提问的话,默认情况下是需要排队的(阻塞),也就是回答完一个人的问题后才会继续回答下一个人的提问,多人使用时体验也不会很好。
如果你是那种不差电费的角色,是可以考虑调整一下ollama释放模型的时间与开启并发的,调整后的服务配置如下
命令:
sudo vim /etc/systemd/system/ollama.service03:ollama服务卸载
如果你不想继续使用ollama了,可以参考如下流程进行卸载
04:手动安装Ollama程序
由于Ollama站点访问有时候不太稳定,导致部分人在使用官网提供的安装命令时可能会安装失败
官网提供的安装命令:
curl -fsSL https://ollama.com/install.sh | sh此时有两个方法可以解决
方法1:换个时间点进行安装尝试,比如早晨起早一点进行安装,速度很快。
方法2:手动安装
05:Linux系统下Ollama的版本更新问题
在Linux下,目前版本的Ollama没有提供对应的升级功能,只能通过官方提供的命令直接进行覆盖安装
命令:
curl -fsSL https://ollama.com/install.sh | sh当然了,如果你是手动安装的 Ollama 程序,则只需要再次从GitHub网站上下载对应的新文件进行解压替换即可
网站:Ollama的GitHub地址
06:跨源资源共享(CORS)配置
对于部分希望在浏览器插件中调用本地大模型算力的情况,比如“沉浸式翻译”
需要在Ollama服务配置文件中间添加跨源资源共享(CORS)配置,添加完成后重启服务生效
命令:
vim /etc/systemd/system/ollama.service07:待定